Analyzing Coffee with Data Science + ChatGPT Code Interpreter
What makes the best coffee? I upload a dataset about coffee to ChatGPT and use it to clean the data automatically, understand insights, and generate cool charts.
One of my favorite new features of ChatGPT is the “code interpreter,” which allows ChatGPT to execute code and read data files you upload.
You can upload a data file, then ask ChatGPT questions, and ChatGPT will write code to analyze the data and create visualizations based on your questions. Now you can produce excellent visualizations based on data with minimal effort.
It’s surprisingly intelligent, where ChatGPT will look at the structure of your data, automatically clean it, and decide how to analyze it.
I found an interesting dataset on Kaggle called “Coffee Quality Data”. It contains coffee reviews, with 100-point scores, along with information about the coffee, such as its country of origin, altitude, preparation method, and variety, and information about its flavor profile, such as acidity and sweetness.
I’m interested in examining this dataset to answer questions like: “Which countries produce the best coffee?” and “What are the differences in flavor profiles between countries and preparation methods?
The code interpreter mode in ChatGPT allows you to upload a data file and ask questions about it.
Loading and Cleaning Data
One of my favorite features of the ChatGPT code interpreter is its ability to clean data and do a preliminary analysis quickly.
The coffee dataset is of decent quality but has quite a few issues, like missing data, poorly formatted data, and low sample sizes for some data. This is usually a manual, laborious process and is inconvenient for quick exploratory analysis. The ChatGPT code interpreter does an excellent job of automatically detecting the most critical data and fixing problems.
It starts by writing code to load the dataset and printing it to discover the most important columns of data.
# First, let's load and inspect the dataset
import pandas as pd
# Load the data
df = pd.read_csv('/mnt/data/coffee_data.csv')
# Display the first few rows of the dataframe
df.head()
ChatGPT is able to understand a lot about the data and how to analyze it just by seeing a sample. Here’s its analysis:
The dataset contains 44 columns.
Here are a few key ones: Species: The species of the coffee bean. Owner: The owner of the coffee farm. Country.of.Origin: The country where the coffee bean was grown. Farm.Name: The name of the coffee farm. Altitude: The altitude at which the coffee was grown. Region: The region where the coffee was grown. Processing.Method: The method used to process the coffee beans. Aroma, Flavor, Aftertaste, Acidity, Body, Balance, Uniformity, Clean.Cup, Sweetness, Cupper.Points: These are the scores given to the coffee on various attributes by a professional coffee taster (cupper).
Our target variable would be Total.Cup.Points as we are trying to find out what makes the best coffee. The higher the total cup points, the better the coffee is considered to bee.
For our analysis, we’ll mainly focus on the factors that might affect the coffee quality, such as Country.of.Origin, Variety, Processing.Method, Altitude, and sensory profiles (Aroma, Flavor, Aftertaste, Acidity, Body, Balance).
Analyzing Data
It starts with a quick analysis to show the distribution of the most important data points.
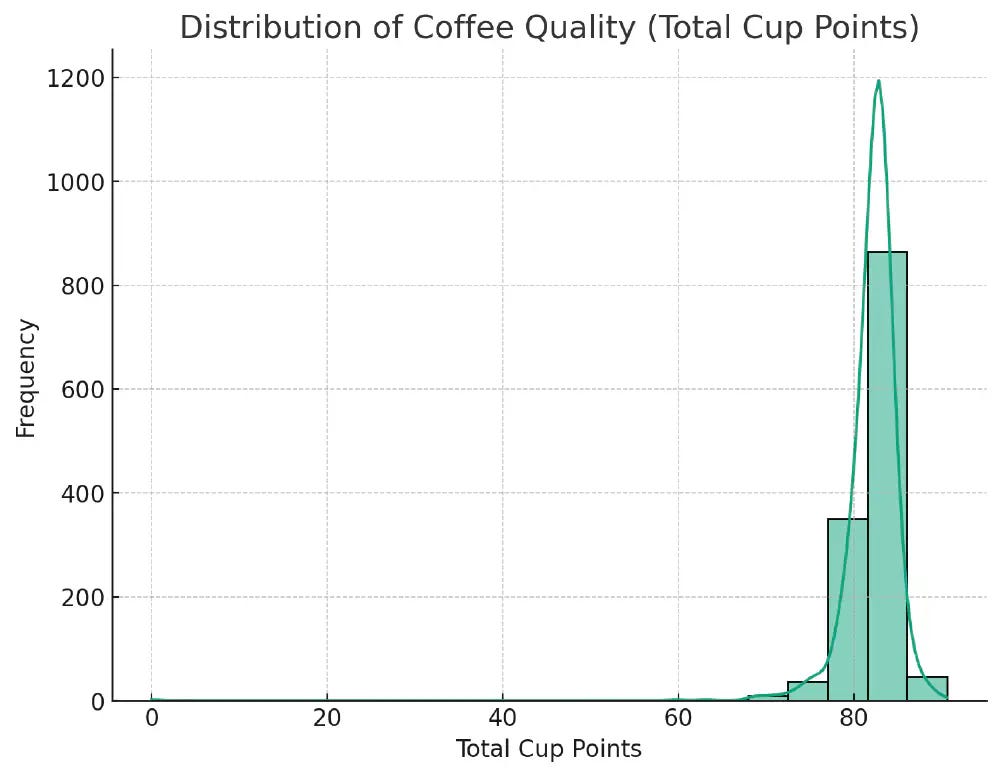
Distribution of Ratings
The left plot shows the distribution of the total cup points, representing the coffee’s overall quality. The distribution is approximately normal, with a slight skew towards higher scores, indicating that most of the coffee in this dataset is of good quality.
Initial plot to show overall shape of data. Skewed towards high reviews in this case.
Initial Analysis
Next, ChatGPT does a more detailed analysis by automatically graphing what it thinks are the most important pieces of data.
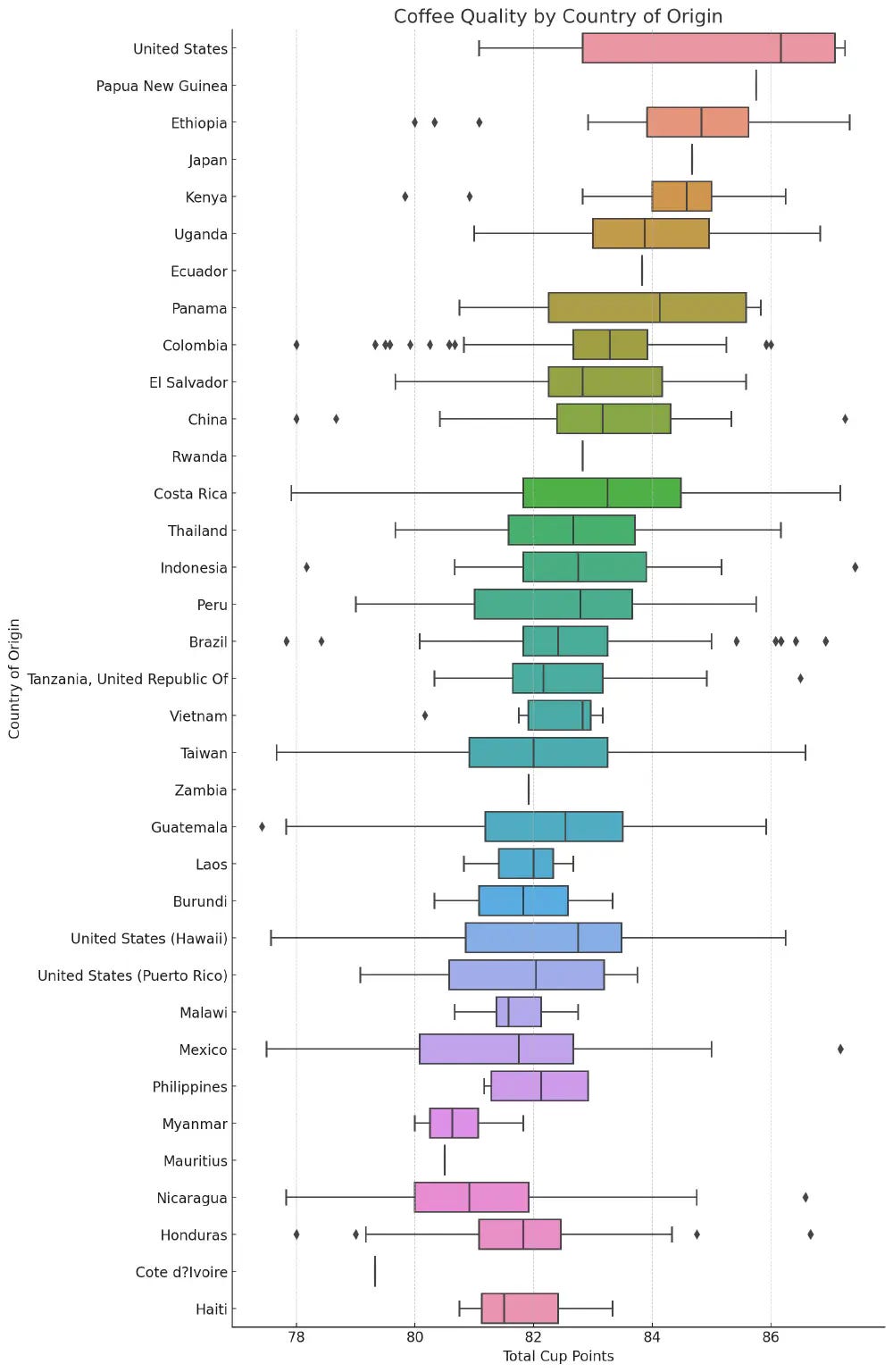
Next, let’s examine the relationships between coffee quality (Total.Cup.Points) and some potentially influential factors (Country.of.Origin, Variety, Processing.Method, altitude_mean_meters, and sensory profiles). We will use box plots to visualize these relationships. For the sake of clarity, we’ll only consider the top 5 categories for Country.of.Origin, Variety, and Processing.Method. For sensory profiles, we’ll use scatter plots to see the correlation with Total.Cup.Points.
The visualizations suggest that:
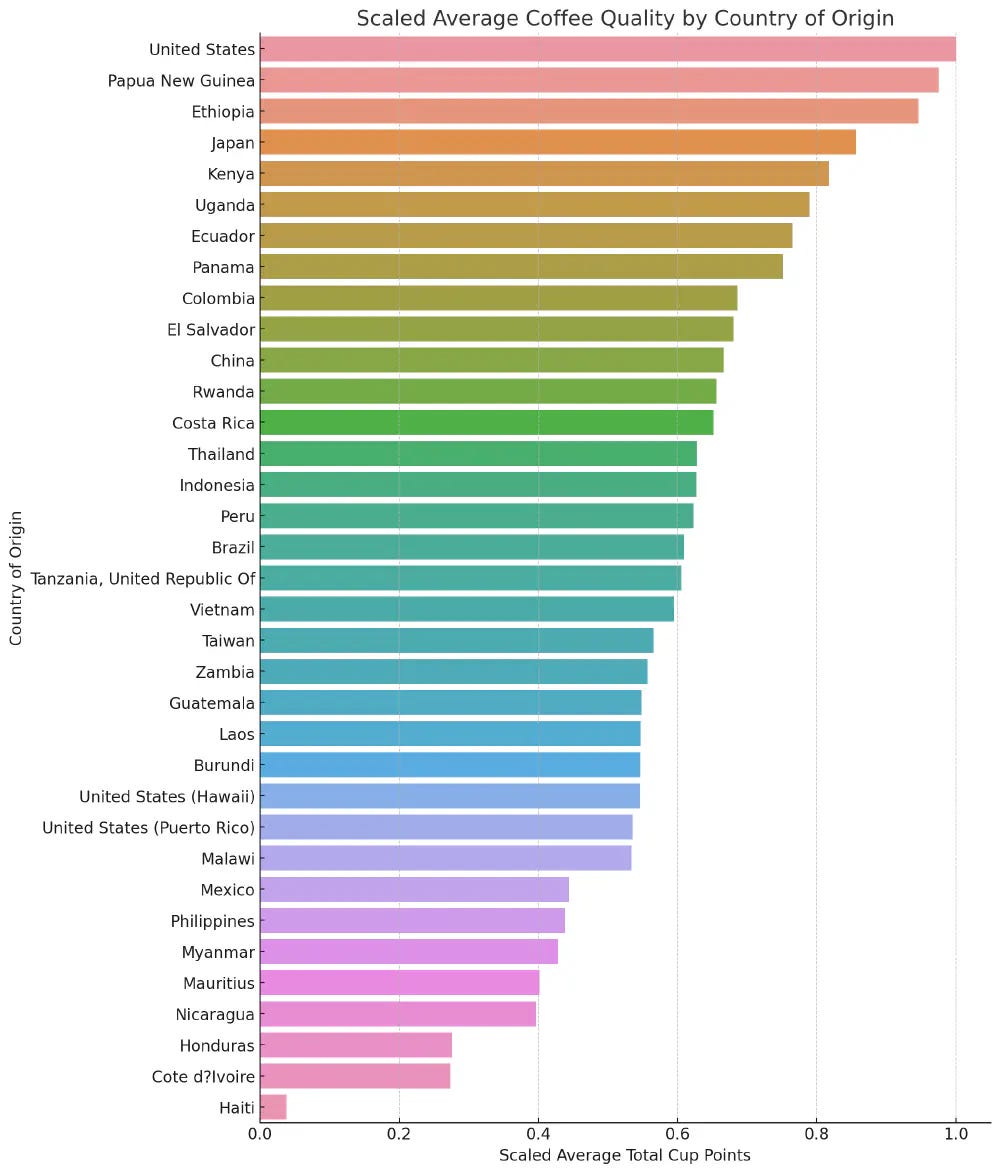
The highest average coffee quality is from the United States, Papua New Guinea, Ethiopia, Japan, and Kenya.
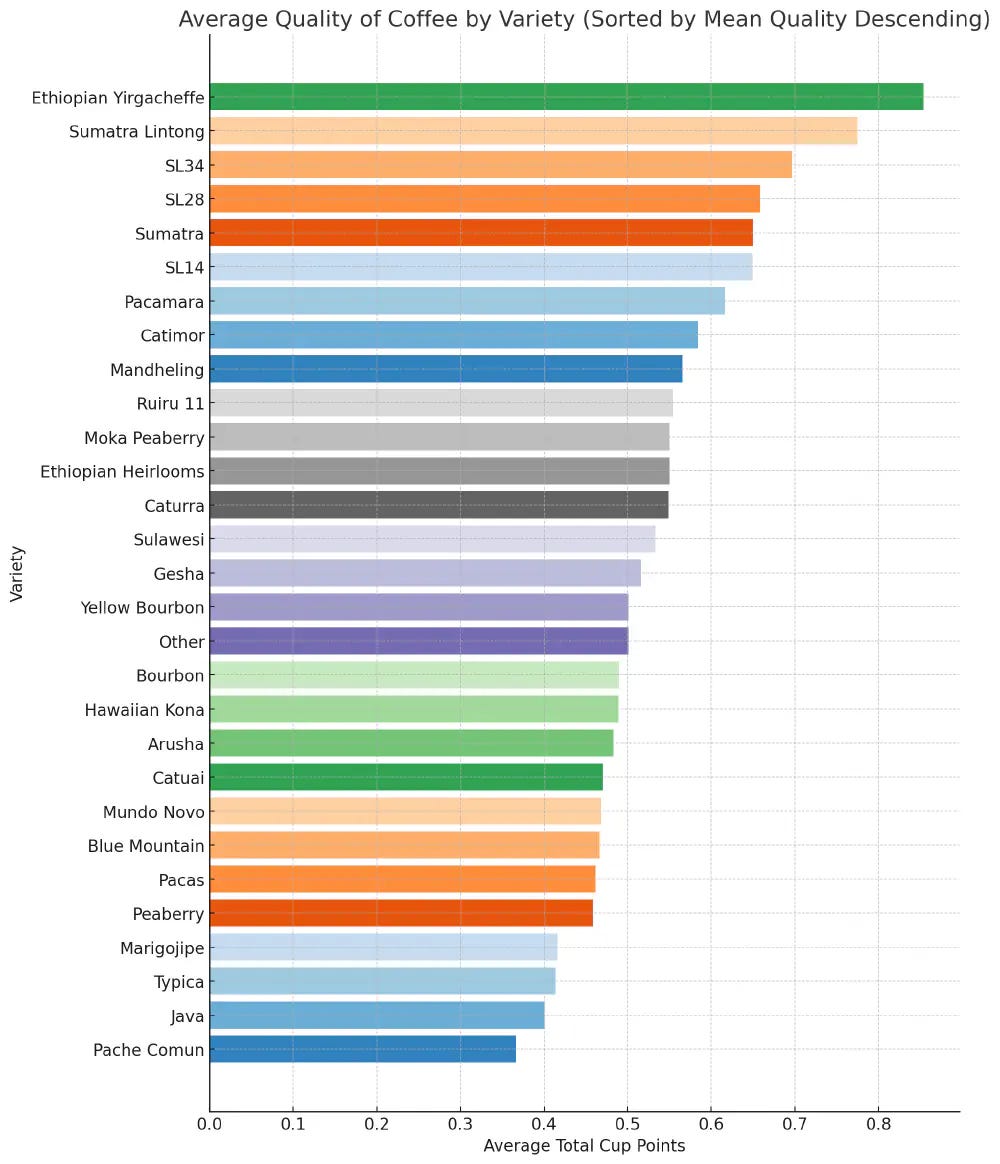
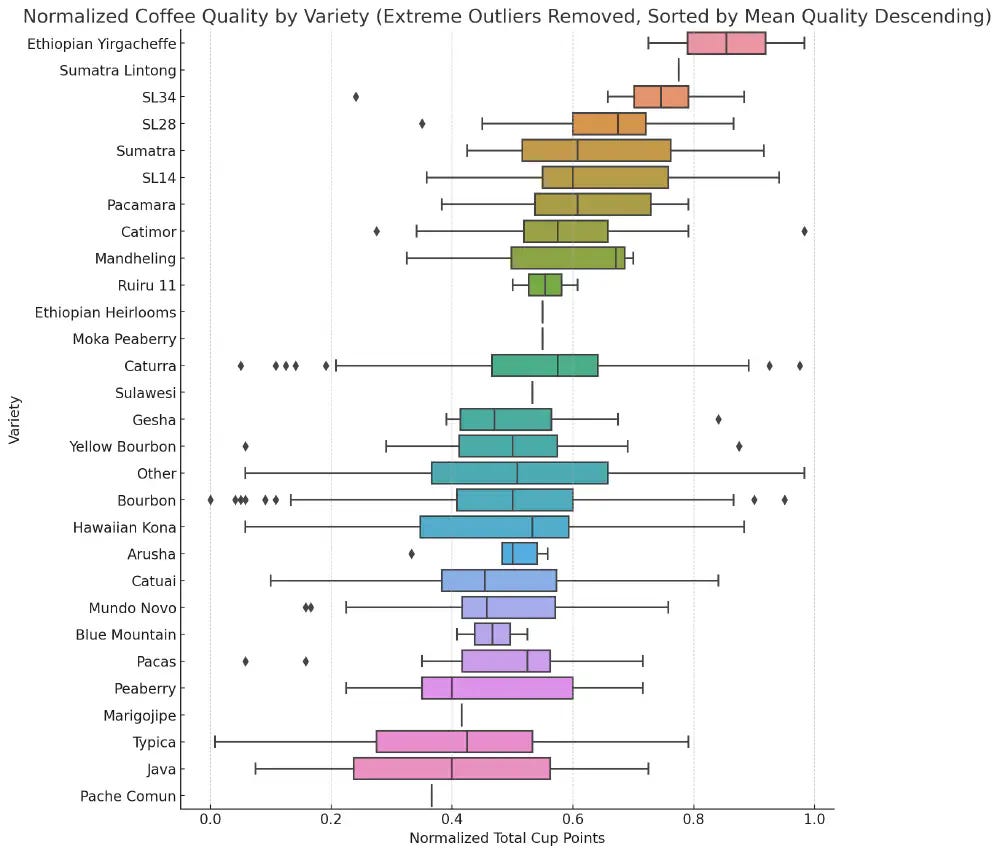
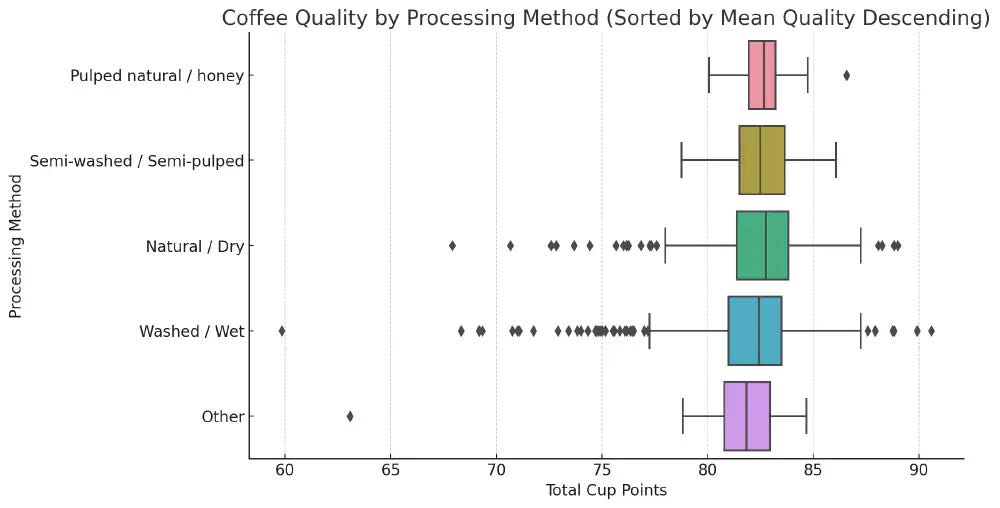
The Yirgacheffe variety and the “Pulped natural / honey” processing method are associated with superior coffee quality.
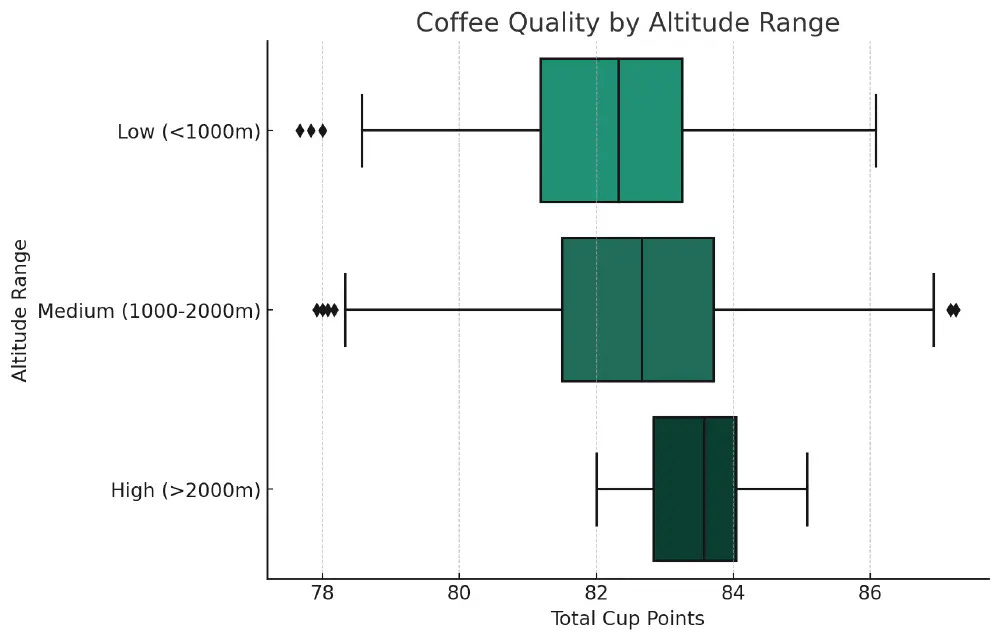
Aroma and flavor scores have a strong positive correlation with coffee quality. Altitude does not exhibit a clear correlation with coffee quality.
Visualizations
I continued asking it questions to generate visualizations, such as “Generate a bar chart for top mean cup scores by country, sorted in descending order.
Here are some of my favorite visualizations
Coffee Quality by Country
Coffee Quality by Variety
Coffee Quality by Altitude Range
The median coffee quality increases with altitude, suggesting that coffee grown at higher altitudes tends to have slightly higher quality.
Quality by Processing Method
Processing method refers to how the bean is prepared before roasting.
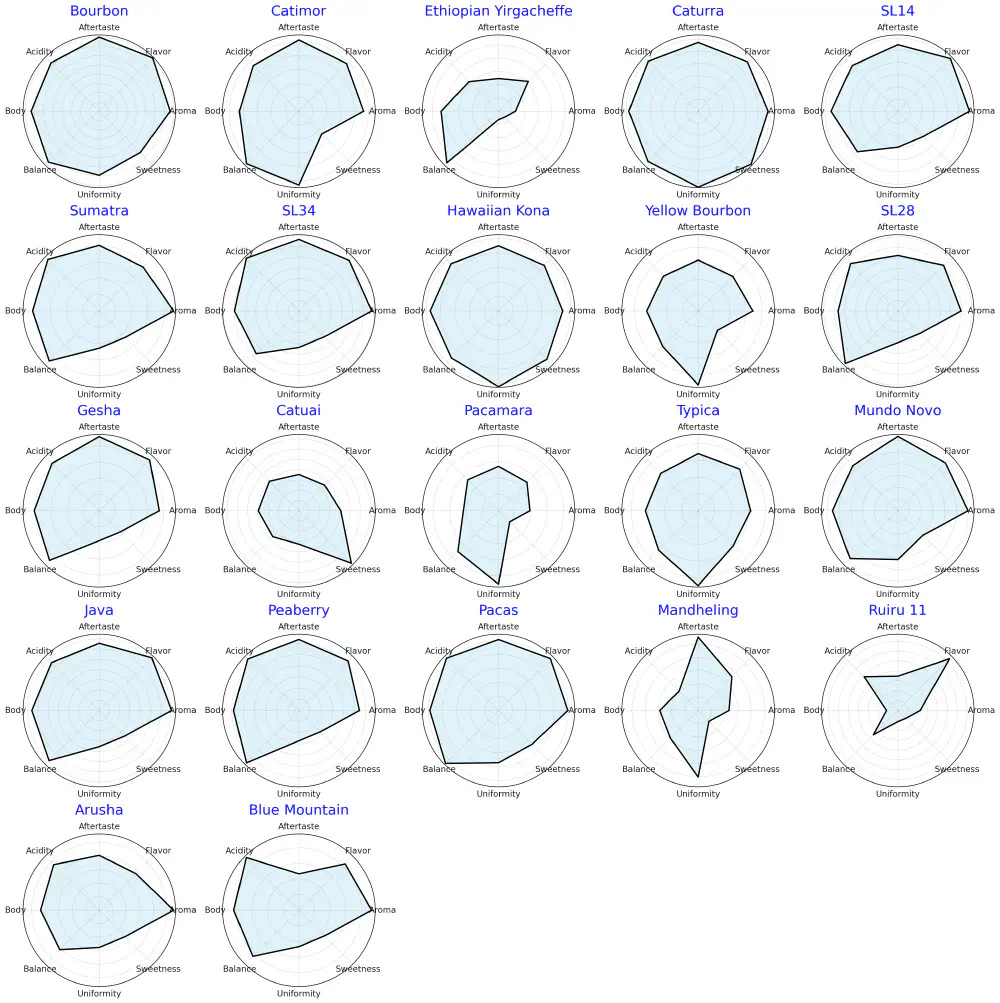
Flavor Profile by Variety
How the different varieties compare on different flavor profiles, such as sweetness and acidity.
This uses an interesting chart called a “Radar Chart” where each point shows the intensity of the flavor profile.
Flavor Profile by Country
Flavor Profile by Country
Conclusion
The code interpreter of ChatGPT has been proving immensely useful for exploratory data analysis. This tool makes it much easier to do data science without an in-depth understanding of Python machine learning and charting libraries.
I had fun extracting insights and generating cool visualizations from the Kaggle coffee dataset with very little knowledge of the libraries needed.
ChatGPT was able to automate almost all of the data cleaning and code to generate visualizations.
The main limitation is the Code Interpreter is limited to a handful of preinstalled libraries, but I could imagine this being extremely powerful when it’s able to install and run any library.
I’m impressed with how intelligent the tool is and have overall had good results uploading datasets and asking questions about the data.
Thank you for reading this post. I’d really appreciate it if you shared it!